


Data warehouses encourage procrastination
You say "store it first, clean it later"?

Batch processing aka “store it first, clean it later” mindset has destroyed the culture of data engineering teams. It has introduced procrastination with handling garbage data or privacy violations, leading to “data-debt”. I too was a perpetrator and victim of this debt in my past roles.
There are arguments for and against implementing data quality at the data warehouse layer. The primary advantage is that it is more efficient as data can be processed in batches. The disadvantage is that it’s too late and data has already reached all downstream systems and requires re-processing and backfilling.

No data engineer has ever enjoyed reprocessing data. “Can you do a backfill?” were the most horrific words you could say to my team. It means lost productivity, disruption to the flow, and an invitation to more unknown problems.
I have been speaking with a few data engineering teams about data quality - and most talk about data quality “at rest”. There is very little effort and urgency in enforcing data contracts and quality at the source of the data. Even if teams are most diligent with their process, they lack the tools to take action on data issues before it becomes debt.
Data quality needs to be solved at ingestion
Event streams such as app engagements, impressions or backend logs are the blood supply for analytics and ML systems. Kafka and the likes of stream processing is growing, with strong testament from Confluent’s >50% Y/Y revenue growth in the past few quarters.
Most data engineering teams reserve the use of stream processing for only a few sets of applications. Rightfully, because stream processing:
Requires tighter hygiene on quality of data.
Managing state is harder (e.g. hydrating or joining properties).
Needs a mature engineering team to design with tighter constraints.
Additionally, tooling is not yet commoditised for vertical applications such as parameterised bot/spam detection (stateless data) or streaming inference. It is still pretty complex to set up with cloud offerings. Expecting organisations to clean data or detect privacy violations while streaming is a tough, yet rewarding mountain to climb.
Due to varied ownership, Data Engineers do not control the source or do not control the ingestion process (real-time or not). But being as close to the source as possible - e.g. the hourly raw logs table or the 5-minute granularity S3 files is still a better place to enforce and fix issues. Even for organisations that control 1st party data sources, within their control, processes are broken:
Data quality needs to be solved while planning
When a team plans to launch a new feature, they need to make sure they track events to measure its success. This is usually done by creating a list of these events in a spreadsheet or a doc. However, these lists don't guarantee that every event will be tracked accurately, which can cause issues for data analysts who rely on this data. They may discover problems like missing events or mistakes in the data, and have to ask mobile engineers to fix them.
However, mobile engineers are busy working on new features and fixing old events is never a high priority. Even if a fix is made, it may take a long time to reach everyone who uses the app, meaning that old, incorrect data can still end up in the data warehouse.
There are a few pieces of tooling that exist that can help with the above process but have the following limitations:
Data Catalog software such as Alation, Informatica and Colibra focus on “Datasets” and are not geared to be the planning tools for “Events” collection.
Customer Data Platforms such as Segment, Mixpanel, or Amplitude provide “Tracking Plan” but they are only used within the realm of Analytics, and require migration to their schema and/or Client SDKs.
Data Quality tools such as Monte Carlo Data, Bigeye, Great Expectations also focus on detecting issues but less on helping the teams fix issues in a timely / real-time manner.
What is the solution?
Let's go back to the fundamentals here. A lot of the debugging and tech-debt minimization principles from core Software Engineering fundamentals can be applied to Data Engineering, which is a good starting point.
Data Contracts: APIs have strict contracts with backend teams and frontend teams and similarly Data producers and consumers can have stricter data contracts. Chad and Adrian cover this in great detail in their blog and I will not go into the details. This includes having well-defined schemas, in a schema registry along with type-safe SDKs and ETL libraries used ubiquitously across instrumentation, ingestion and data warehouses.
People and Processes: Lack of a clear understanding of the priority of clean events with data producers is a process problem. Explicit buy-in and working agreements to follow tracking plans and remediate issues as they appear, help build the right culture. It is quite similar to how teams set up code reviews and unit testing for general software engineering.
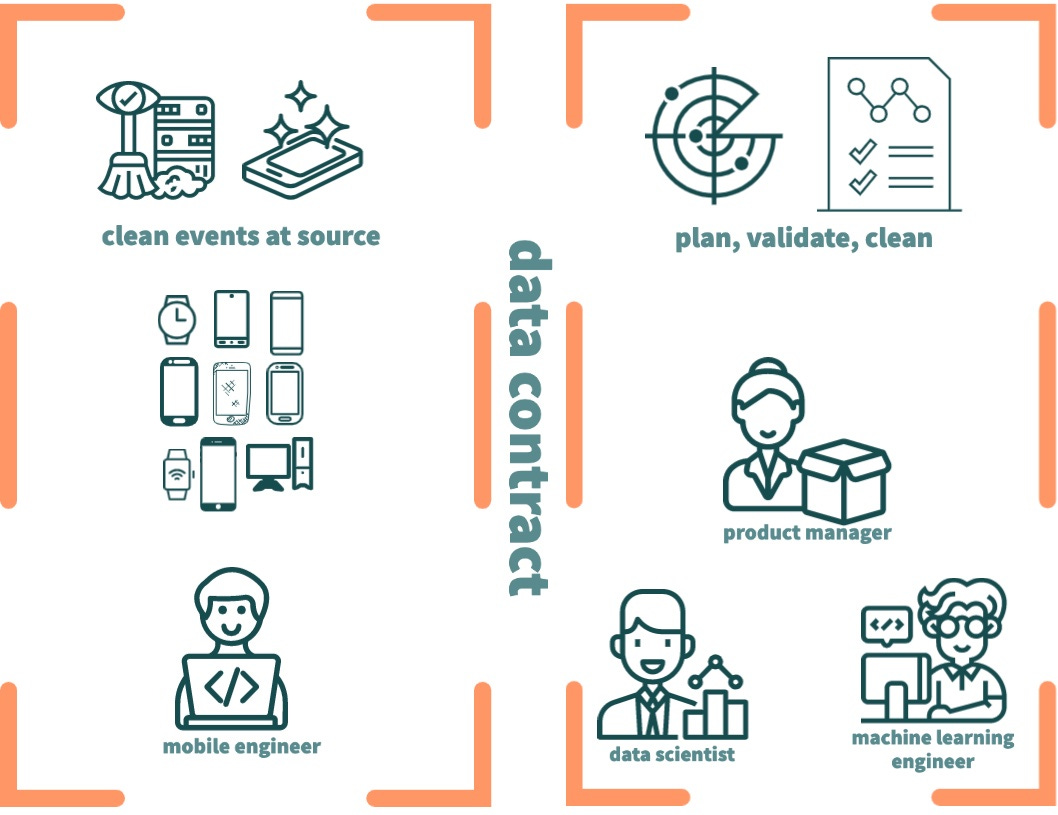
Ultimately, I believe there is a gap here in implementing and enforcing data contracts, data quality automation and how Data Producers (i.e. mobile engineers, backend engineers) work with Data Consumers (i.e. data analysts, ML Engineers). Given how many humans are involved in this process, getting to clean data will take more than a feature-rich tool. It will require writing bug-free code and empowering more people to do quicker fixes when issues are found. Data quality and healing needs to “shift left”, towards the source of the data.
Really interesting article, and agree with your point on assuring clean data from the source. Not sure if your article explicitly called this out, but to me from the source starts with the system we set up for data capture, e.g. if you want a form to collect age, make sure it has a strict type. Seeing as I am from the data side, one question i have for you, is how can we enable data teams, specifically the analysts and scientists to play a bigger role in the data logging process. Tools like Segment and Amplitude are great, and analysts can even write the snippet, but at the end of the day, few companies allow their data teams to actually commit code.
Maybe, the answer is to develop a whole new process for logging data, what do you think?